BigQuery guide
The following guide will help you start using BigQuery with Quary. By the end of this guide, you will have a BigQuery instance, a Quary dataset inside it, and a Quary project that you can use to run queries and push views.
Prerequisites
Before you can get started, you will need the following:
- A Google Cloud Platform account
- A Google Cloud Platform project with BigQuery enabled
- Quary extension installed
- Data inside the BigQuery project to query
Base setup
Create your target dataset
Quary requires a dataset to be created inside your BigQuery project. This dataset will be used to store all the views that you create with Quary. To create a dataset, follow the steps below:
- Open the BigQuery console.
- Select your project from the dropdown in the top left.
- Click the Create dataset button.
For more details on creating a dataset, see the BigQuery documentation.
Create a Quary project
To create a Quary project, open Visual Studio Code with the Quary extension installed and signed in. Once signed in, create a new project by opening the command palette and running the Quary: Initialise Project command. This should open a new window as follows:

After clicking on the BigQuery button, you will be prompted through a sign-in flow to connect your Google Cloud Platform account to Quary. The steps are as follows:
- Click on Next to continue.
- Allow Visual Studio Code to open a browser window.
- Sign in to your Google Cloud Platform account.
- Click on Allow to allow Quary to access your BigQuery project.
- Copy the code shown to you.
- Press
Proceedin Visual Studio Code in the bottom right and paste the code into the input field
After completing the steps above, you should be able to select your BigQuery project and dataset from the dropdown. Select the project and dataset you created in the previous steps.
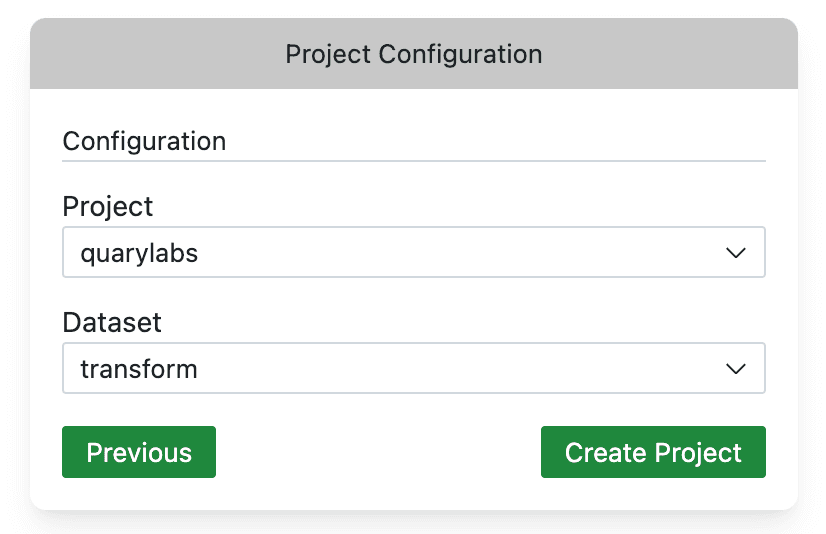
Once you hit Create Project, Quary will create some files in your directory. These are the configuration files for your project. In addition to this, Quary will also open the Import Sources tab.
Import sources
The Import Sources tab allows you to import tables and views from your BigQuery project into Quary. Once a table, or view, has been imported, you can use it in your queries just by referencing it by name, prefixed with q., like you would refer other models. To import the source, select the sources you want to import and click on the Import Sources button. The path at the top is the path where the source will be imported to. You can change this to your liking.
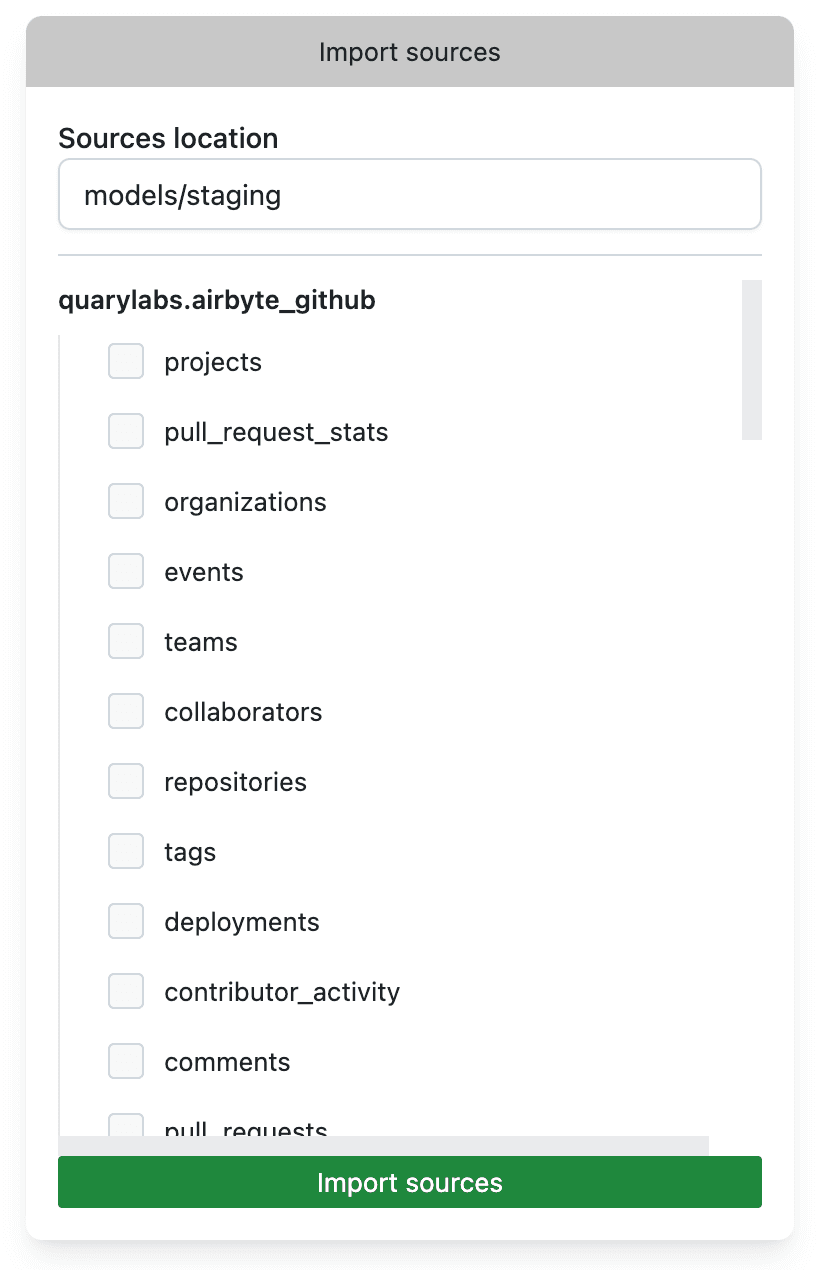
Import sources will add the following for each source:
- A
sourcereference in theschema.yamlfile. - A
stg_source.sqlmodel in the directory that intermediates the source. - Documentation for the model also in the
schema.yamlfile.
Create your first model
Once you have those sources imported, you should be able to query them in your models, just as documented in the first model guide.
CI
GCP Keyless authentication
There are many ways to authenticate from GitHub Actions to BigQuery. The simplest way would be to use a service account key and place it in your GitHub repository. However, this is not recommended. Rather than do this, we will use the keyless authentication method described here. You could either follow the guide or use the following Terraform config, with replaced local variables.
locals {
project_id = "<gcp_project>"
dataset = "<quary_bigquery_dataset>"
organization = "<github_organisation>"
repo = "<github_quary_repo>"
}
provider "google" {
project = local.project_id
region = "eu-west-1"
}
resource "google_iam_workload_identity_pool" "github_pool" {
project = local.project_id
workload_identity_pool_id = "github-pool"
display_name = "GitHub pool"
description = "Identity pool for GitHub deployments"
}
resource "google_iam_workload_identity_pool_provider" "github" {
project = local.project_id
workload_identity_pool_id = google_iam_workload_identity_pool.github_pool.workload_identity_pool_id
workload_identity_pool_provider_id = "github-provider"
attribute_mapping = {
"google.subject" = "assertion.sub"
"attribute.actor" = "assertion.actor"
"attribute.aud" = "assertion.aud"
"attribute.repository" = "assertion.repository"
}
attribute_condition = "assertion.repository==\"${local.organization}/${local.repo}\""
oidc {
issuer_uri = "https://token.actions.githubusercontent.com"
}
}
resource "google_service_account" "github_actions" {
project = local.project_id
account_id = "github-actions"
display_name = "Service Account used for GitHub Actions"
}
resource "google_service_account_iam_member" "workload_identity_user" {
service_account_id = google_service_account.github_actions.name
role = "roles/iam.workloadIdentityUser"
member = "principalSet://iam.googleapis.com/${google_iam_workload_identity_pool.github_pool.name}/attribute.repository/${local.organization}/${local.repo}"
}
data "google_bigquery_dataset" "dataset" {
dataset_id = local.dataset
project = local.project_id
}
resource "google_project_iam_custom_role" "custom_bigquery_role" {
project = local.project_id
role_id = "CustomBigQueryJobCreator"
title = "Custom BigQuery Job Creator"
description = "Custom role with permissions to create BigQuery jobs"
permissions = [
"bigquery.jobs.create",
"bigquery.tables.list"
// Add any other specific permissions required for your use case
]
}
resource "google_project_iam_member" "bigquery_custom_role" {
project = local.project_id
role = "projects/${local.project_id}/roles/${google_project_iam_custom_role.custom_bigquery_role.role_id}"
member = "serviceAccount:${google_service_account.github_actions.email}"
}
resource "google_bigquery_dataset_access" "workload_identity_user" {
dataset_id = data.google_bigquery_dataset.dataset.dataset_id
role = "WRITER"
user_by_email = google_service_account.github_actions.email
}
resource "google_bigquery_dataset_access" "workload_identity_user_airbyte_github" {
dataset_id = data.google_bigquery_dataset.dataset_github.dataset_id
role = "READER"
user_by_email = google_service_account.github_actions.email
}
locals {
github_actions_sa_email = google_service_account.github_actions.email
workload_identity_provider = "${google_iam_workload_identity_pool.github_pool.name}/providers/${google_iam_workload_identity_pool_provider.github.workload_identity_pool_provider_id}"
}
output "workload_identity_provider" {
value = local.workload_identity_provider
}
output "service_account" {
value = local.github_actions_sa_email
}
data "github_repository" "repo" {
full_name = "${local.organization}/${local.repo}"
}
output "repo_url" {
value = data.github_repository.repo.html_url
}This should create the required resources in your GCP project, such that the GitHub Actions service account can authenticate to BigQuery. Depending on your use case, you may need to add additional permissions to the service account, like access to the other datasets in your BigQuery project that you import.
Finally, you may also want to restrict the branches that have privileges to deploy to your BigQuery dataset, by modifying the attribute_condition in the google_iam_workload_identity_pool_provider resource.
GitHub Actions
Now that we have the required resources in GCP, we can set up GitHub Actions to deploy and test changes to our BigQuery dataset.
Running tests
First, we will set up a workflow to run tests on pull requests. This will ensure that any changes to the dataset are tested before they are deployed.
Create a new file in your GitHub repository at .github/workflows/pr.yml with the following contents. Note: Remember to change the branch if your default branch is not main.
name: pr-checks
on:
pull_request:
branches:
- main
jobs:
quary-compile:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: quarylabs/install-quary-cli-action@main
- run: quary compile
quary-build-dry-run:
permissions:
contents: read
id-token: write
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: google-github-actions/auth@v1
id: google_auth_step
with:
workload_identity_provider: ${{ secrets.GCP_WORKLOAD_IDENTITY_PROVIDER }}
service_account: ${{ secrets.GCP_SERVICE_ACCOUNT }}
token_format: access_token
- uses: quarylabs/install-quary-cli-action@main
- run: quary build -d
env:
GOOGLE_CLOUD_ACCESS_TOKEN: ${{ steps.google_auth_step.outputs.access_token }}
quary-test:
permissions:
contents: read
id-token: write
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: google-github-actions/auth@v1
id: google_auth_step
with:
workload_identity_provider: ${{ secrets.GCP_WORKLOAD_IDENTITY_PROVIDER }}
service_account: ${{ secrets.GCP_SERVICE_ACCOUNT }}
token_format: access_token
- uses: quarylabs/install-quary-cli-action@main
- run: quary test -s --mode skip
env:
GOOGLE_CLOUD_ACCESS_TOKEN: ${{ steps.google_auth_step.outputs.access_token }}This adds three jobs:
- A quick compile step
- A dry run build step which outputs the required sql
- A test step which runs the tests
Deploying changes
Next, we will set up a workflow to deploy changes to the dataset. This will ensure that any changes to the dataset are deployed to the dataset when changes are merged to your default branch. Note: Remember to change the branch if your default branch is not main. Create a new file in your GitHub repository at .github/workflows/main.yml with the following contents.
on:
push:
branches:
- main
jobs:
build:
permissions:
contents: read
id-token: write
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: google-github-actions/auth@v1
id: google_auth_step
with:
workload_identity_provider: ${{ secrets.GCP_WORKLOAD_IDENTITY_PROVIDER }}
service_account: ${{ secrets.GCP_SERVICE_ACCOUNT }}
token_format: access_token
- uses: quarylabs/install-quary-cli-action@main
- run: quary build -c
env:
GOOGLE_CLOUD_ACCESS_TOKEN: ${{ steps.google_auth_step.outputs.access_token }}
test:
permissions:
contents: read
id-token: write
needs: build
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: google-github-actions/auth@v1
id: google_auth_step
with:
workload_identity_provider: ${{ secrets.GCP_WORKLOAD_IDENTITY_PROVIDER }}
service_account: ${{ secrets.GCP_SERVICE_ACCOUNT }}
token_format: access_token
- uses: quarylabs/install-quary-cli-action@main
- run: quary test
env:
GOOGLE_CLOUD_ACCESS_TOKEN: ${{ steps.google_auth_step.outputs.access_token }}